



ChatGPT一出,學界,、工業(yè)界無不驚為天人,。一位研究機構(gòu)的資深研究員就對AI科技評論說過:“ChatGPT出來,,直接給我們整不會了——生成做的比我們好就不說了,NLP(自然語言處理)能力還比我們強不少,。”
微軟注資百億美元,,谷歌則如臨大敵,ChatGPT在科技圈里掀起的巨浪,,仍是現(xiàn)在進行時,。
但是,ChatGPT并非“萬能鑰匙”——大模型在某些專業(yè)領(lǐng)域的準確度,,仍然無法超越其他垂類產(chǎn)品,。
近日,騰訊AI Lab 就通過實驗證明,,在機器翻譯領(lǐng)域,,ChatGPT在某些情況下,能力弱于其他商業(yè)翻譯產(chǎn)品,。
 論文地址:https://arxiv.org/pdf/2301.08745v1.pdf
論文地址:https://arxiv.org/pdf/2301.08745v1.pdf
1,、ChatGPT是個好翻譯嗎?
騰訊AI Lab的調(diào)查文指出:
首先,,在高資源環(huán)境——如歐洲語言上——ChatGPT的表現(xiàn)與商業(yè)翻譯產(chǎn)品(如谷歌翻譯,、DeepL Translate)相比具有競爭力,但是,,在低資源環(huán)境明顯落后,,如古代語言;
其次,,在翻譯的魯棒性上,,ChatGPT在生物醫(yī)學摘要、或Reddit評論方面表現(xiàn)不如商業(yè)翻譯產(chǎn)品,,但是在口語方面也許會是一個很好的翻譯工具,。
為了更好地理解ChatGPT的翻譯能力,騰訊AI Lab從以下三個方面開展實驗:
提示詞(prompt)翻譯:
ChatGPT是一個大型語言模型,,在翻譯時需有提示詞(prompt)作為引導才能引導系統(tǒng)進行翻譯,。所以,,提示詞的風格會影響翻譯輸出的質(zhì)量,。例如,,在多語言機器翻譯模型中,如何將兩種語言信息聯(lián)系起來非常重要,,這通常是通過附加語言標記來解決,。
多語言翻譯:
ChatGPT是一個處理各種NLP任務(wù)并涵蓋不同語言的單一模型,可以被視為一個統(tǒng)一的多語言機器翻譯模型,。因此,,ChatGPT在資源差異(如高與低)和語系差異(如歐洲與亞洲)上的表現(xiàn)是該實驗所探討的重點之一。
翻譯魯棒性:
ChatGPT是基于GPT-3開發(fā)的模型,,GPT-3在涵蓋各種領(lǐng)域的大規(guī)模數(shù)據(jù)集進行上訓練,,因此,在特定領(lǐng)域的表現(xiàn),,是這次研究者們的重點之一,。
提示詞翻譯
為了設(shè)計觸發(fā)ChatGPT機器翻譯能力的提示詞,騰訊AI Lab團隊向ChatGPT提出以下prompt:
提供十個可以讓你翻譯的簡明提示或模版
并獲得圖1中的結(jié)果:
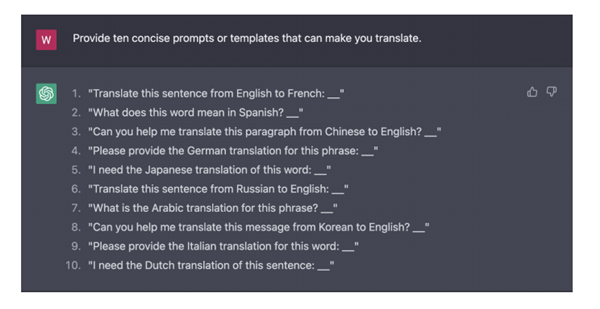 圖1: ChatGPT推薦的10個可引發(fā)其進行機器翻譯的prompt
圖1: ChatGPT推薦的10個可引發(fā)其進行機器翻譯的prompt
生成的提示語看起來很合理,,但是都有相似的格式,,研究人員將它們總結(jié)成三個候選prompt(如圖2),其中[SRC] 和 [TGT] 分別代表翻譯的源語言和目標語言,。
另外,,研究人員在Tp2中增加了一個額外命令,要求ChatGPT不要在翻譯的句子上加雙引號(在原始格式中經(jīng)常發(fā)生),。
盡管如此,,ChatGPT依舊不穩(wěn)定,如會將同一批次的多行句子翻譯成單行,。
 圖2:候選翻譯提示
圖2:候選翻譯提示
研究人員將三種不同的候選prompt與Flores-101的測試集在漢譯英任務(wù)中的表現(xiàn)進行比較,,圖3顯示了ChatGPT和其他三個翻譯軟件的結(jié)果。
雖然ChatGPT提供了相當好的翻譯,,但它仍然落后于基線至少5.0個BLEU點,。
關(guān)于三個候選prompt,Tp3在所有指標方面表現(xiàn)的最好,,因此在這篇論文中,,研究者默認使用Tp3。
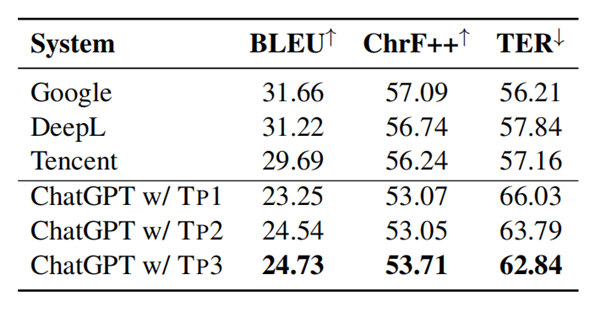 圖3:在中譯英翻譯任務(wù)中ChatGPT使用不同提示語的翻譯表現(xiàn)對比
圖3:在中譯英翻譯任務(wù)中ChatGPT使用不同提示語的翻譯表現(xiàn)對比
多語言翻譯
騰訊AI Lab選擇了四種語言來評估ChatGPT在多語言翻譯中的能力,,包括德語(De),、英語(En)、羅馬尼亞語(Ro)和中文(Zh),,這些語言在研究和競賽中都被普遍采用,。
前三種語言同來自拉丁語系,,而后一種則來自中文語系。
研究人員測試了任意兩種語言間的翻譯表現(xiàn),,共涉及12次翻譯,。
資源差異
通過實驗發(fā)現(xiàn),在同語系中不同語言也存在資源差異,。在機器翻譯中,,德英互譯通常被認為是一個高資源任務(wù),有超過1000萬條語料,,羅馬尼亞語與英語間互譯語料要少得多,。
如圖4所示,ChatGPT在德譯英和英譯德上,,與谷歌翻譯和DeepL可以分庭抗禮,;而在羅馬尼亞語譯英,和英譯羅馬尼亞語方面,,則要明顯落后,。
具體來說,ChatGPT在英譯羅馬尼亞語上獲得的BLEU分數(shù)比谷歌翻譯低了46.4%,。
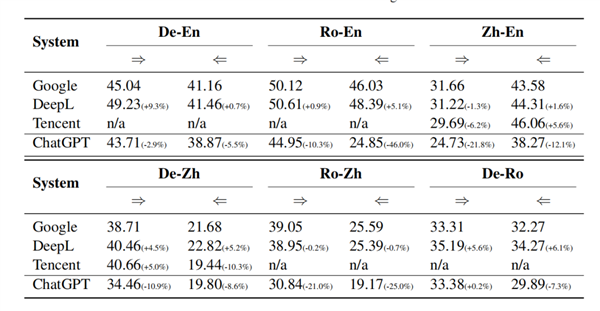 圖4:ChatGPT在多語言翻譯中的表現(xiàn)
圖4:ChatGPT在多語言翻譯中的表現(xiàn)
研究者認為,,英語和羅馬尼亞語之間的單一語言數(shù)據(jù)的巨大資源差異,限制了羅馬尼亞語的語言建模能力,,這部分解釋了將英語翻譯成羅馬尼亞語表現(xiàn)差的原因,。
相反,羅馬尼亞語譯成英語可以受益于強大的英語建模能力,,使平行數(shù)據(jù)的資源缺口可以得到一定程度的補償,。
語系
同時,研究人員也考慮了語系的影響,。
通常認為,,對于機器翻譯,不同語系之間的翻譯通常比同一語系間翻譯更難,。
研究人員發(fā)現(xiàn),,德英互譯、漢英互譯,,或者德漢互譯在文化和書寫方式上存在差異,。
另外可以發(fā)現(xiàn),在這幾種翻譯中,,ChatGPT和幾款商業(yè)翻譯軟件間差距較大,,研究者認為,這是因為在同一語系中知識轉(zhuǎn)移比在不同語系間要好,,對于既是低資源又來自不同語系的語言來說(如羅馬尼亞語和漢語的互譯),,這種差距會進一步擴大,。
由于ChatGPT在一個模型中處理不同的任務(wù),低資源的翻譯任務(wù)不僅與高資源的翻譯任務(wù)競爭,,而且還與其他NLP任務(wù)競爭模型容量,,這說明其性能表現(xiàn)欠佳。
翻譯魯棒性
騰訊AI Lab進一步評估了ChatGPT在WMT19 Bio和WMT20Rob2和Rob3測試集上的翻譯魯棒性,,這些測試集引入了領(lǐng)域偏見和潛在的噪聲數(shù)據(jù),。
例如WMT19 Bio測試集是由Medline摘要組成的,,這需要特定領(lǐng)域的知識處理,,WMT20Rob2是來自Reddit的評論,可能包含各種錯誤,,如拼寫錯誤,、單詞遺漏、插入重復,、語法錯誤,、破壞性語言,和網(wǎng)絡(luò)俚語等,。
圖5列出了BLEU分數(shù),,顯然ChatGPT在WMT19 Bio和WMT20Rob2測試集上的表現(xiàn)不如谷歌翻譯和DeepL Translate。
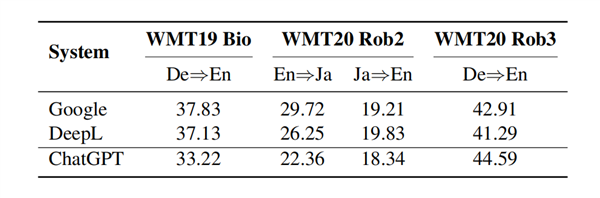 圖5:ChatGPT在翻譯魯棒性方面的表現(xiàn)
圖5:ChatGPT在翻譯魯棒性方面的表現(xiàn)
原因可能在于,,像谷歌翻譯這樣的商業(yè)翻譯產(chǎn)品往往需要不斷提高其翻譯特定領(lǐng)域(如生物醫(yī)學)或噪音句子的能力,,因為它們是現(xiàn)實世界的應(yīng)用,需要對分布之外的數(shù)據(jù)有更好地概括性,,ChatGPT不太能夠完成這一點,。
不過,一個有趣的發(fā)現(xiàn)是,,ChatGPT在包含眾包語音識別語料的WMT20Rob3測試集上大大超過了谷歌翻譯和DeepL Translate,。
這表明,ChatGPT本質(zhì)上是一個人工智能對話工具,,能夠比商業(yè)翻譯軟件生成更自然的口語(見圖6),。
 圖6:來自WMT20魯棒集set3的例子
圖6:來自WMT20魯棒集set3的例子
2、ChatGPT應(yīng)如何揚長避短,?
從該研究可知,,高舉高打的ChatGPT每訓練一次就耗費大量算力資源,但也不能在全領(lǐng)域盡善盡美,。
所以,,一些人開始思考,是否應(yīng)該“摒棄”大模型思路,,轉(zhuǎn)而去做“精耕細作”的小模型,。
騰訊AI Lab在Chat GPT“測評”中提到,,羅馬尼亞語與英語互譯,相較德英互譯存在較大差距,,原因在于:巨大資源差異,,限制了羅馬尼亞語的語言建模能力,也恰恰證明,,AI學習能力常常受到低資源的掣肘,。
但也有資深學者認為,盡管現(xiàn)時ChatGPT仍存在不少不足之處,,但仍然對研究者和創(chuàng)業(yè)者有著不少啟示,。
以ChatGPT為代表的AI 3.0走的是跟過去 AI 浪潮不一樣的路,即更落地,、更接近真實世界,,在工業(yè)應(yīng)用上,更直接,,更落地,,從學術(shù)研究到工業(yè)落地的路徑也變得更短、更快,。
未來,,“helpful, truthful, harmless”的 AI 系統(tǒng)會成為現(xiàn)實。
文章出處:雷峰網(wǎng)







